好玩的API调用之一——星座API和爬虫平时写程序经常需要用到一些服务,比如翻译、天气预报、星座等,我通常会使用爬虫来为这些服务提供网站爬取数据,但是有些网站有对爬虫的限制很多,有些关键词会定期改变,就像中国天气网经常改变HTML标签的class值,需要爬虫不断维护,而聚合数据API只为普通用户提供免费的API接口,这是简直就是垃圾,而且网上有些网站其实有开放的API供开发者调用,所以我想把我发现的有趣的API和我写的爬虫写一个博客主题供大家参考,并且我会继续添加和维护它们。 第二个话题是关于星座查询。 我通常在无聊的时候使用这个。 也可以将其显示在网站上。 以前我都是直接爬生肖屋网站上的数据来分析。 后来我找到了汇总数据。 提供了这个API,调用的方法也很简单。 我今天就把这两个方法写出来,有需要的可以自己参考一下。 1. 这是十二生肖之家的网站
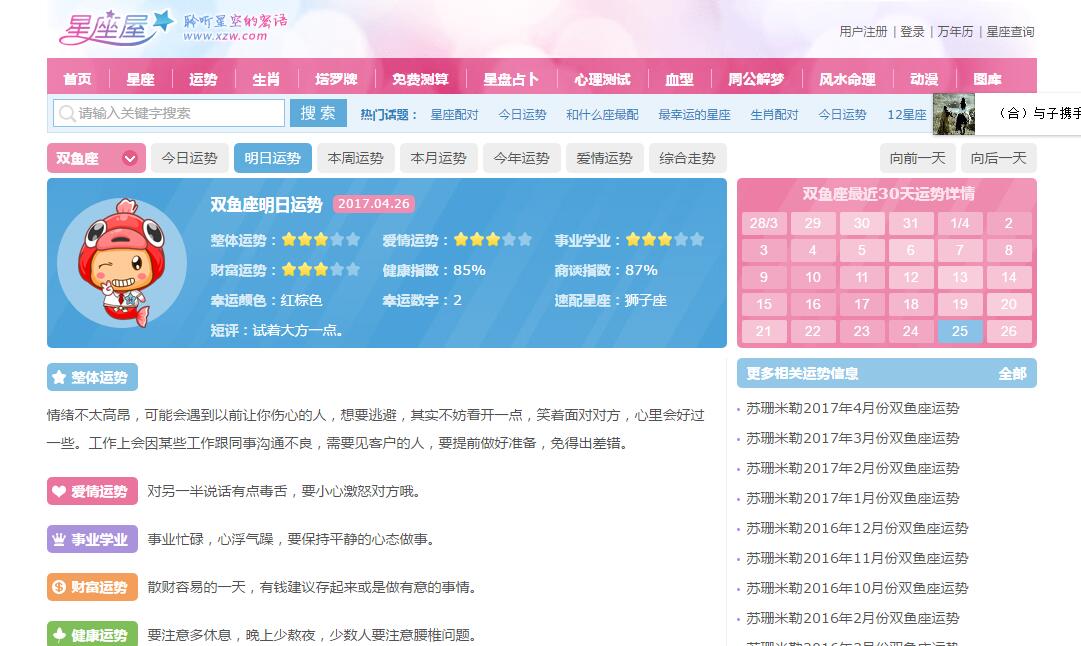
然后写个爬虫直接爬就行了,我直接放出代码,不解释
#-*- coding=utf8 -*-
import sys
import MySQLdb
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
from bs4 import BeautifulSoup
import time
def download(url,headers):
try:
request = urllib2.Request(url,headers=headers)
html = urllib2.urlopen(request).read()
# html = urllib2.urlopen(url).read()
except urllib2.URLError as e:
print "error"
print e.code #可以打印出来错误代号如404。
print e.reason #可以捕获异常
html = None
return html
def save(html):
f = open('thefile.txt', 'w')
f.write(html)
f.close()
def read_file():
f = open('thefile.txt', 'r')
html = f.read()
f.close()
return html
def get_html(url):
User_agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0'
headers = {'User_agent': User_agent}
html = download(url, headers)
save(html)
def constellation():
url = 'http://www.xzw.com/fortune/pisces/1.html'
get_html(url)
html = read_file()
soup = BeautifulSoup(html)
# print soup.find_all('dl')
html2 = soup.find('div', class_='c_cont')
html2 = str(html2)
soup = BeautifulSoup(html2)
text = '双鱼座明日运势:' + '\n'
text = text + '整体运势:' + soup.find_all('span')[0].string + '\n'
text = text + '事业学业:' + soup.find_all('span')[2].string + '\n'
text = text + '健康运势:' + soup.find_all('span')[4].string + '\n'
return text
# html = urllib2.urlopen(url)
# print html
if __name__=='__main__':
weather_text = weather()
2.先在聚合数据里注册,然后提交身份证照片进行个人认证,很烦人,最后在免费数据里找到星座,就这样了
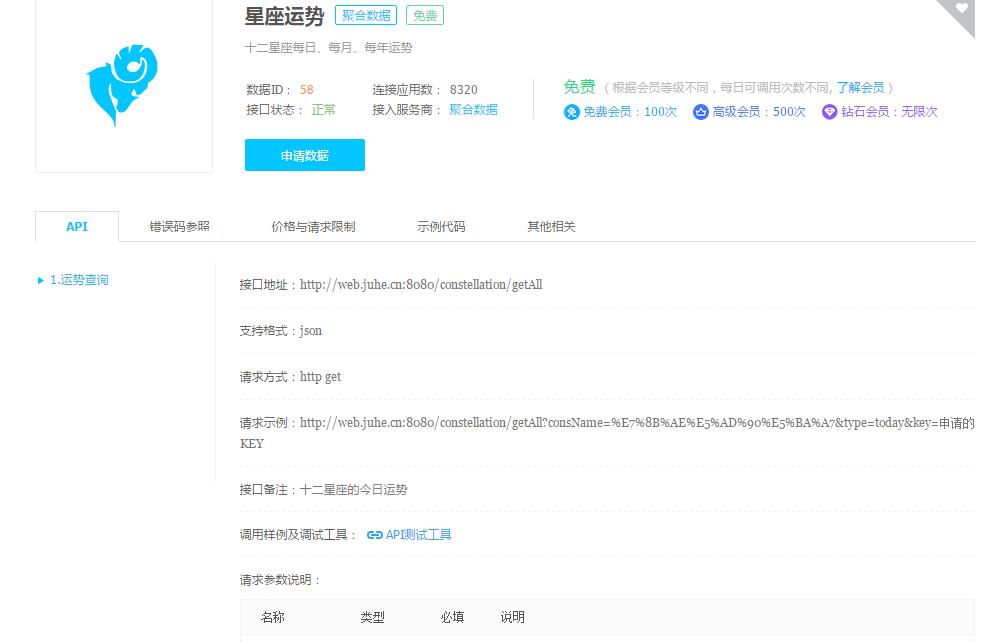
然后点击申请数据,然后再次验证,不过很快就过去了。 我在控制台中找到了自己的密钥。 我用它来处理数据。 以下是代码。 只需用你的钥匙替换钥匙即可。 至于类型,根据需要切换今天、周、年等。
#-*- coding=utf8 -*-
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
import urllib2
import json
from bs4 import BeautifulSoup
def download(url):
html = urllib2.urlopen(url)
return html.read()
#星座运势api的调取
def constellation():
today_url = 'http://web.juhe.cn:8080/constellation/getAll?consName=双鱼座&type=today&key='
tomorrow_url = 'http://web.juhe.cn:8080/constellation/getAll?consName=双鱼座&type=tomorrow&key='
html = download(tomorrow_url)
json_html = json.loads(html)
text = ''
text = text + str(json_html['name']) + ' ' + str(json_html['datetime']) + ' 明日运势 \n';
text = text + '综合指数:' + str(json_html['all']) + '\n'
text = text + '幸运色:' + str(json_html['color']) + '\n'
text = text + '健康指数:' + str(json_html['health']) + '\n'
text = text + '爱情指数:' + str(json_html['love']) + '\n'
text = text + '财运指数:' + str(json_html['money']) + '\n'
text = text + '幸运数字:' + str(json_html['number']) + '\n'
text = text + '明日概述:' + str(json_html['summary']) + '\n'
print text
return text
def main():
text = constellation()
if __name__ == "__main__":
main()